Jako że w BIG DATA wzrosło zapotrzebowanie na nierelacyjne bazy danych, powstały rozwiązania umożliwiające przechowywanie dużej ilości danych cześciowo ustrukturyzowanych.
Definicja
Jako że fraza powstała na twiterze, to trudno to zdefiniować, natomiast zazwyczaj termin NoSQL dotyczy:
- baz nierelacyjnych
- w tych rozwiązaniach zazwyczaj SQL nie jest głównym sposobem manipulacji danymi
- większość to OSS
- większość działa na klastrach
Raczej nie NO SQL ale Not Only SQL - mądre w chuj, aż 4 slajdy to tłumaczyły
Brak określonej schemy
Rekordy mogą dostawać nowe pola bez zmiany struktury tabeli. Potrzebna jest więc denormalizacja, czyli celowe powielenie danych i spowodowanie redundancji. Pozwala na optymalniejszy odczyt - bo nie musisz joinować.
Baza column family
Rekord ma postać:
- klucz
- para (kolumna, wartość)
- para (kolumna, wartość) …
W każdym miejscu zbiór kolumn może być inny, liczba kolumn w każdym wierszu może być inna.
Kolumny grupuje się wg. rodziny kolumn, czyli grupa powiązanych ze sobą tematycznie kolumn (dane adresowe klienta, cena produktu itd.)
Wartości tych kolumn nie muszą być atomowe, mogą być tam zawarte wartości złożone. Każda kolumna może również zawierać inny typ danych.
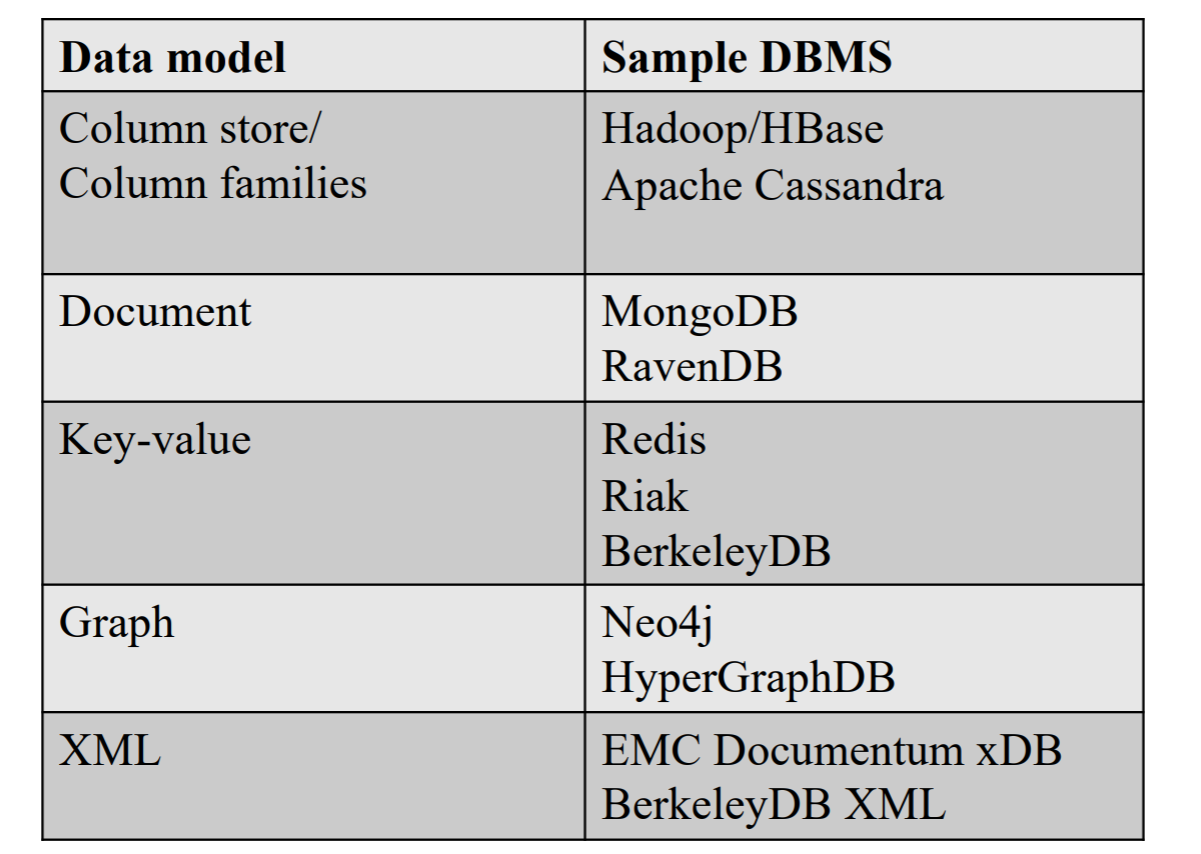
Przykłady baz NoSQL
Agregaty
Zdefiniowana jednostka interakcji z danymi (np. cały jeden order w NorthWind, możliwie wiele rekordów). Istnieją bazy, które wiedzą czym są agregaty (aggregate - based) i takie, które ich istnienie ignorują (aggregate-ignorant). Aggregate based bazy fajnie integrują się z shardingiem, ponieważ dane z tego samego agregatu są wsadzane
Relacyjne bazy i bazy grafowe NoSQL => aggregate-ignorant
Key-value, Rodziny kolumn, document NoSQL => aggregate-based.
Problem z agregatami pojawia się w momencie, gdy transakcja musi dotknąć wielu agregatów leżących na innych maszynach. Zasada ACID nie jest wtedy gwarantowana (jak w przypadku modyfikacji jednego agregatu), obsługę takiego przypadku trzeba obsłużyć samemu w aplikacji klienckiej.
Czy kompletnie nie istnieje schema na danych?
Nie, aplikacja kliencka musi wiedzieć, gdzie mniej więcej trzymane są dane, nazywa się to implicit schema.
Mongo DB
Document based popularna baza NoSQL.

Jeden duży json z danymi na temat jednego zamówienia, aggregate-based podejście.

Tu natomiast znajduje się podejście aggregate - ignorant, wartości są atomowe. Natomiast żeby przetworzyć cały Order, wymagane jest jakieś połączenie rekordów. Jako że SQL nie jest wspierany, to łączenie musi być napisane inaczej, w jakimś API.

Mongo DB wspiera zarówno podejście aggregate-based i aggregate-ignorant.
Apache Cassandra
Kolejna popularna baza NoSQL, oparta na podejściu column-family. Wspiera CQL, czyli uproszczony SQL. Bardzo skalowalna i odporna na błędy.
Fizyczne przetrzymywanie danych w Cassandrze:
- server - maszyna/komputer, RAM, CPU i dysk
- node - maszyna uczestnicząca w klastrze Cassandry, zazwyczaj jeden server uczestniczący, jeden node. Nie zaleca się odpalania wielu instancji Cassandry na jednej maszynie (wtedy jeden server - kilka node)
- rack - logiczna grupa node’ów, służy jako strefa awarii. Ważne, bo przy tworzeniu replik danych, nie tworzy ich się względem tego samego racka. Jeśli padnie rack, dane są dostępne na innym.
- DataCenter - grupa racków, zazwyczaj umieszczona obok siebie fizycznie. Ma własny współczynnik replikacji (patrz Sharding).
- klaster - wszystkie włączone node pracujące razem ze sobą. Wszystkie node w klastrze są równe, nie ma master node.
Use case Cassandry
- wiele data centrów na całym świecie
- przechowywanie dużych objętości danych
Teoria CAP
CAP - Consistency, Availability, Partition tolerance
Wg. Erica Brewera, w rozproszonych systemach zapisywania danych, tylko 2 z 3 własności wymienionych wyżej są osiągalne jednocześnie.
Consistency w tym przypadku jest ważne, gdy dane użytkownika leżą w kilku miejscach jako kopie. Ze względu na problemy połączeniem sieciowym. Najnowszy stan danych może nie być rozesłany do każdej kopii, przez co czytamy stare dane.
Availability to w tym przypadku możliwość otrzymania odpowiedzi na żądanie użytkownika (bez zwrotu błędu), może być niepoprawna.
Partition tolerance miara odporności systemu na błędy sieciowe.
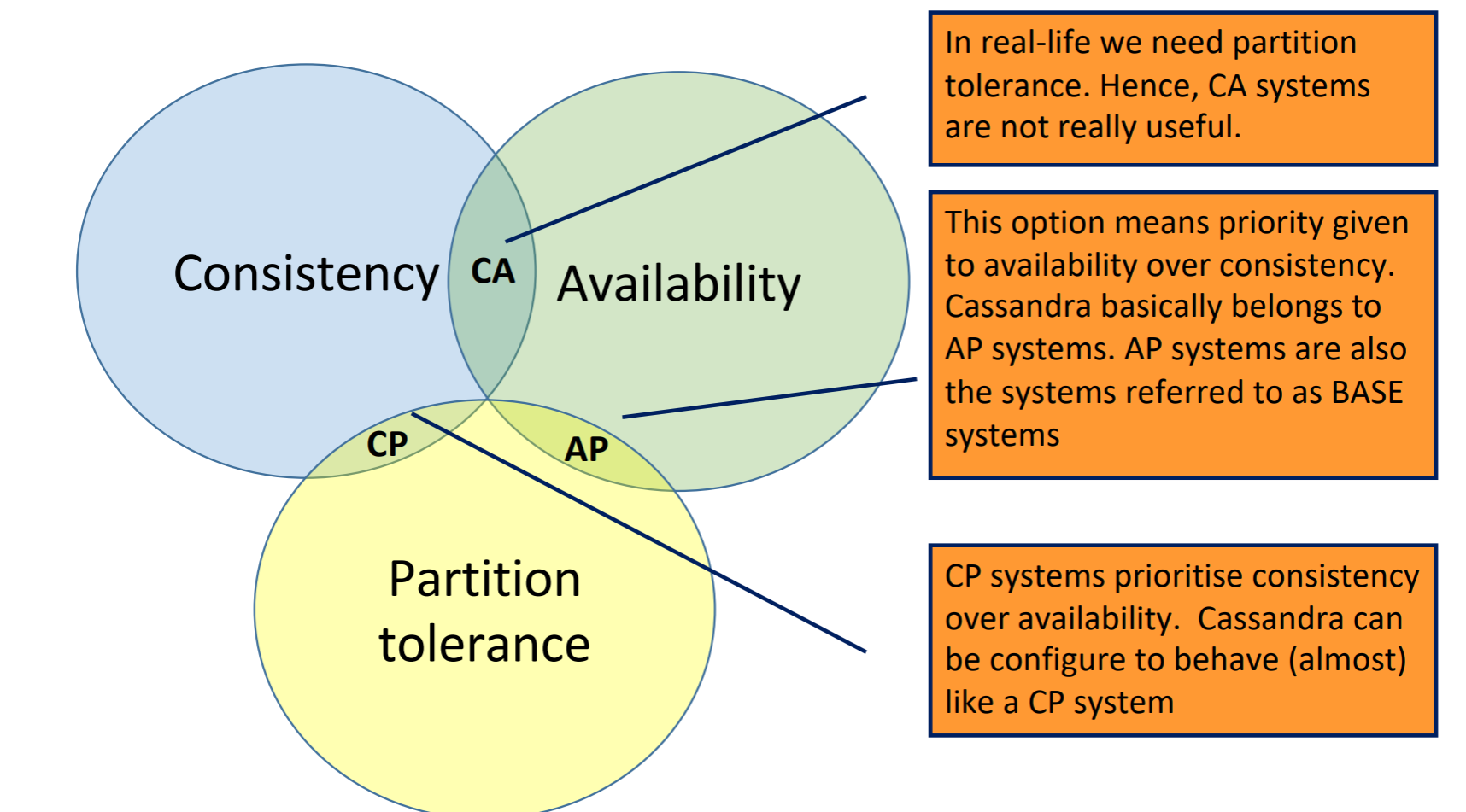
Losowa tabela bo czemu nie
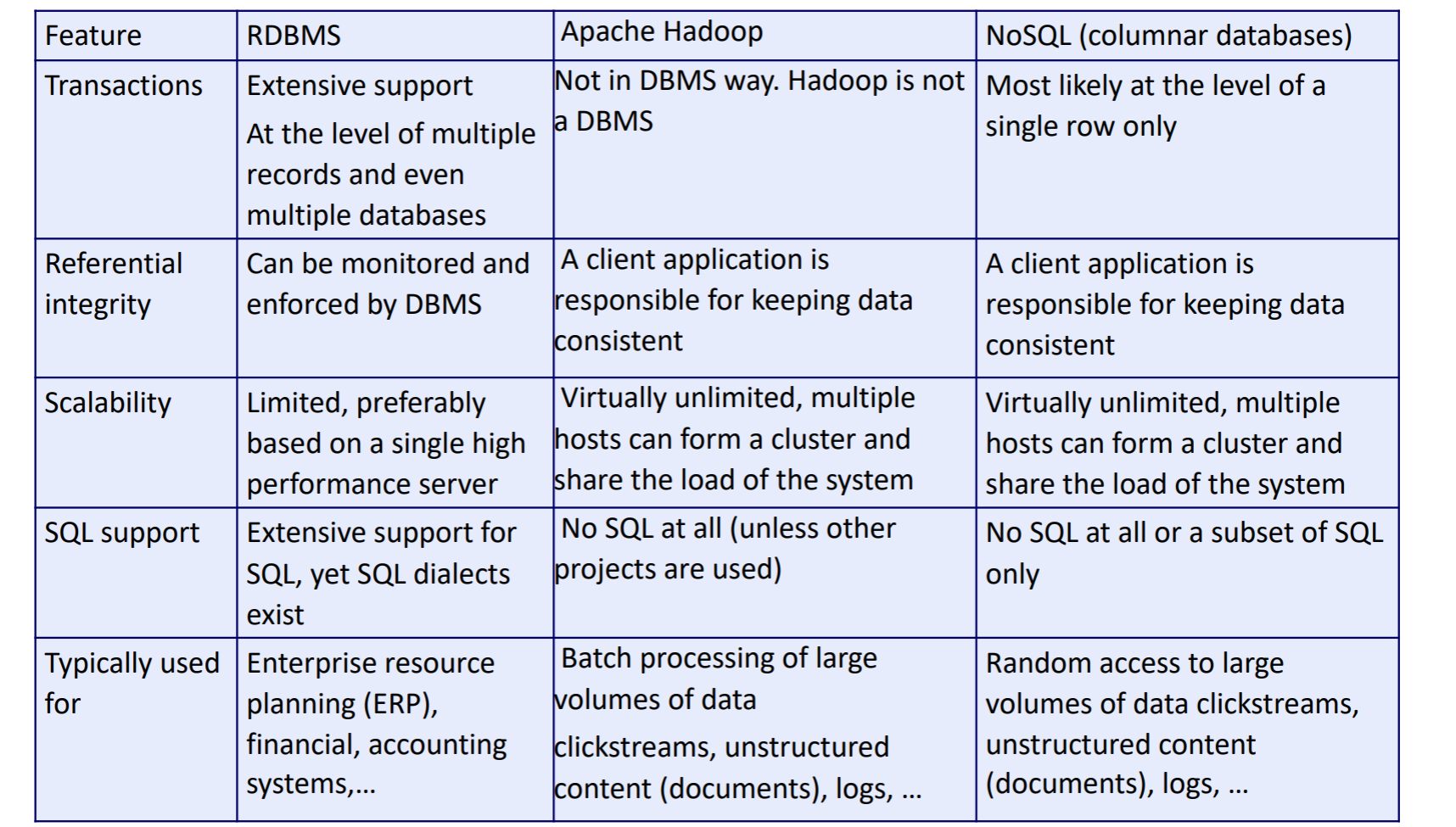
Najważniejszy chyba use case:
- RDBMS - finansowe, biurowe
- Apache Hadoop - masowe przetwarzanie dużej ilości danych
- NoSQL - losowy dostęp do części bardzo dużej ilości danych
Grafowe bazy danych
np. FlockDB, oferują zwiększoną wydajności operacji przeszukiwania, kosztem wydłużonych operacji wsadzania. Głównie do skomplikowanych przesukiwań relacyjnych, wiele JOIN’ów itd.
Zazwyczaj jednoserwerowe. ACID jest wymagany bo graf musi utrzymać poprawną strukturę i łatwy do implementacji no bo jednoserwerowe.