Okazuje się że relacyjne bazy danych i OLTP systemy są słabe do przetwarzania niesamowicie dużych ilości danych. Systemy Big Data działają inaczej.
Standardowe podejście do problemu
- przygotowanie bazy danych przetrzymujących dane na temat jakiegoś problemu
- ekstrakcja do hurtowni danych
- przygotowanie raportów
W przypadku grypy w USA dane były przestarzałe o 1-2 tygodni, ponieważ tyle trwał proces.
Podejście big data
Google na podstawie najczęstszych wyszukań stworzył 450 mln modeli matematycznych, które testowały korelacje wyszukań z raportami opublikowanymi przez CDC. Znalazło 45 haseł silnie skorelowanych z tymi raportami, a następnie zbudowało liniowy model przewidujący rozprzestrzenianie grypy na podstawie lokalizacji. Dane były bardziej rzetelne niż oficjalne raporty rządowe.
Nie potrzebna była żadna wiedza medyczna, wszystko rozwiązane matematycznie.
Wraz z czasem tradycyjne modele big data okazały się mieć dużo fałszywej korelacji z innymi popularnymi hasłami, oraz stwierdzenie o braku wiedzy medycznej okazało się nieprawdziwe.
Definicja big data
Zasoby informacyjne o dużej objętości, prędkości napływu i różnorodności. Wymagają opłacalnych i innowacyjnych form przetwarzania, umożliwiających lepszy wgląd oraz podejmowanie decyzji i automatyzację procesów.
3V - (high volume, velocity, variety).
Główna różnica w podejściach tradycyjnych i big data
Podejście tradycyjne:
- wykorzystuje wiedzę ekspertów do stworzenia dokładnego modelu
- rozwija model
- na podstawie dostępnych danych wysnuwa teorię
Big data: - pobiera jak najwięcej danych
- tworzy wiele (możliwie niepotrzebnych) modeli
- wybiera najlepsze modele wyjaśniające dane oraz traktuje je jako “czarne skrzynki”
Objętość danych
Na podstawie dużej próbki danych na temat użytkownika można wnioskować jego zainteresowania, np.: kategorie książek lub opinie. Można analizować dokładną niszę danego klienta.
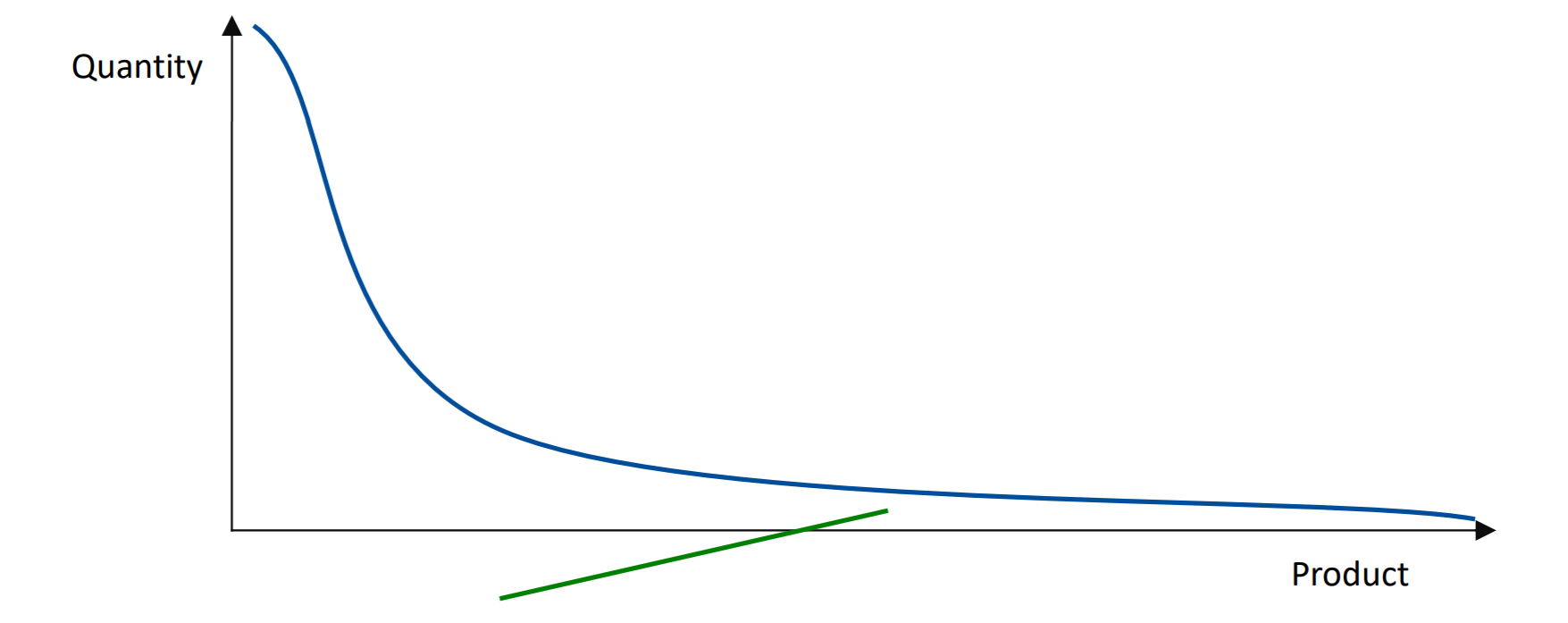
Ten oto chujowy wykres pokazuje produkty (lewo - bestsellery, prawo - ledwie co kupowane niszowe produkty) oraz to w jakich ilościach są kupowane. Pomimo tego, że bestsellery kupowane są bardzo często, jest ich bardzo mało. Produktów niszowych jest masa i pomimo tego że nie sprzedają się tak często, to pole pod wykresem (zysk) jest takie samo. Nazywa się to long tail model, czyli rozwinięcie nisz produktów. To podejście wymaga procesowania dużej ilości danych.
Problem klastra
Skalowalność programów takich jak Facebook był problem za drogim do rozwiązania ciągłym ulepszaniem klastrów obliczeniowych. Rozwiązaniem zostało scaling out czyli kupowanie wiele, zwyczajnych maszyn, gdzie każda miała własny dysk i przetwarzała dane lokalnie, bez bazy relacyjnej.
horizontal vs vertical scaling - kupowanie nowych maszyn kontra ciągłe polepszanie jednej maszyny
Sharding
Proces dystrybucji danych między wieloma serwerami, gdzie każdy z nich operuje na własnym zbiorze danych. Zazwyczaj połączone z replikacjami, żeby dana porcja danych nie była zależna tylko od dostępności jednego serwera.
Współczynnik replikacji - na ilu serwerach istnieje kopia danego sharda.
Wiele serwerów pracujących na tej samej relacyjnej bazie danych osiągają bottleneck w okolicach 50 serwerów. Sharding oferuje lepszą skalowalność.
Apache Hadoop - japierdole
Ważna biblioteka, która umożliwia dystrybucję przetwarzania dużych zestawów danych pomiędzy wieloma serwerami. Ważna w Big Data. Zawiera:
- Hadoop Distributed File System HDFS- podzielony system plików
- MapReduce - system dla równoległego przetwarzania dużych systemów plików.
Podział pracy w Hadoop
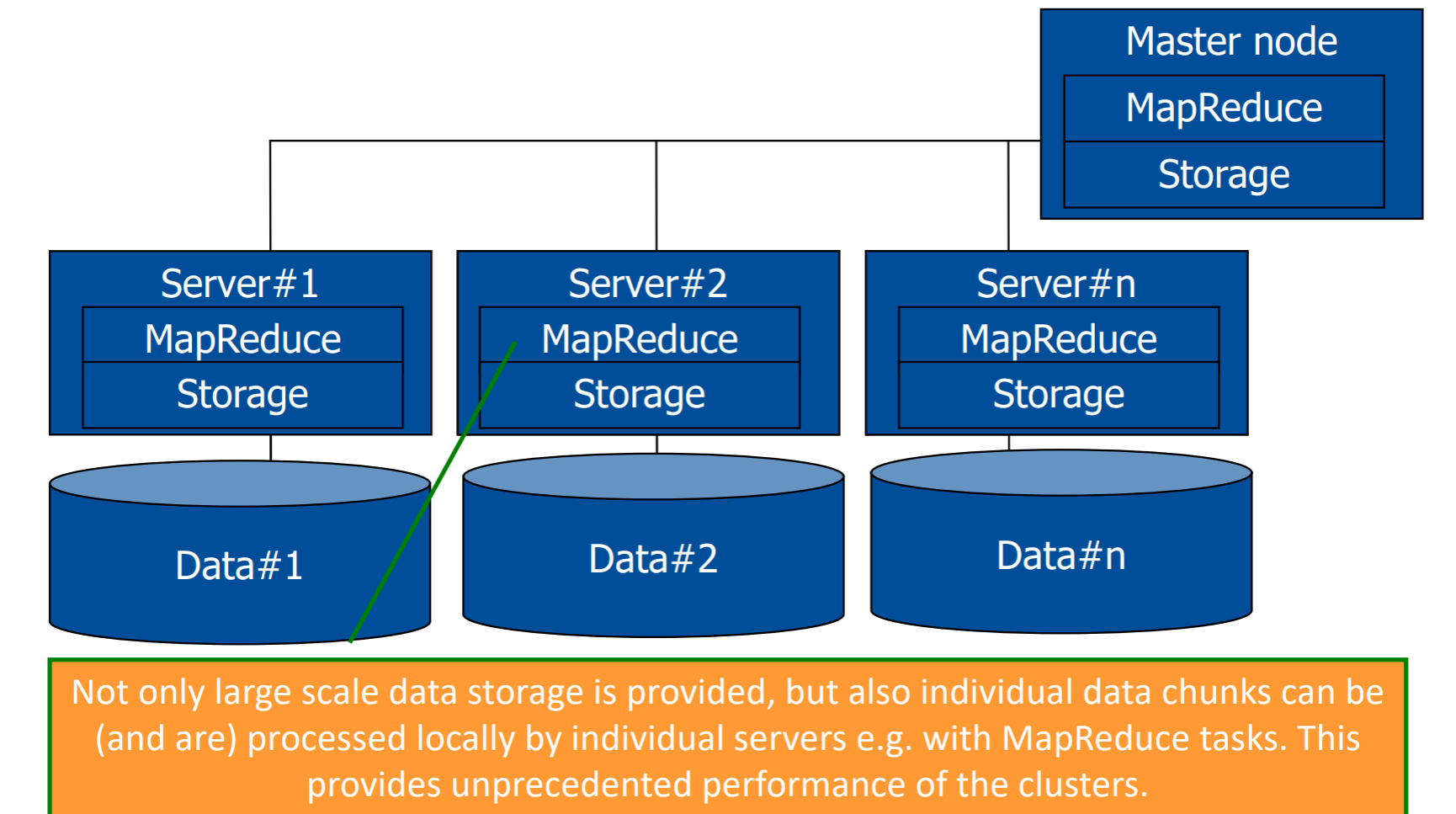
HDFS leży w kawałku data#i każdego węzła, MapReduce to silnik obliczeniowy działający na tym serwerze. HDFS powoduje, że dane leżące w wielu dyskach wielu serwerów wyglądają pozornie na spójne.
Wyrażenia shell dla HDFS
Jako że to jest file system, można wywoływać na nim takie same komendy jak w bashu na zwykłych plikach, lista ze ściągą dla IADu:

Rodzaje danych w Hadoop
- social media data - tweety, posty itd. służące do modelowania uczuć konsumentów
- logi it - wykrywanie włamań, monitorowanie i predykcja zdarzeń, sprawdzanie wydajności
- clickstream data - jak ludzie przemieszczają się po portalu, które części UI zmienić
- sensor data - odczyt z czujników, służy do przewidywania awarii maszyn
- geolocation data - optymalizacja dostaw i redukcja kosztów logistyki