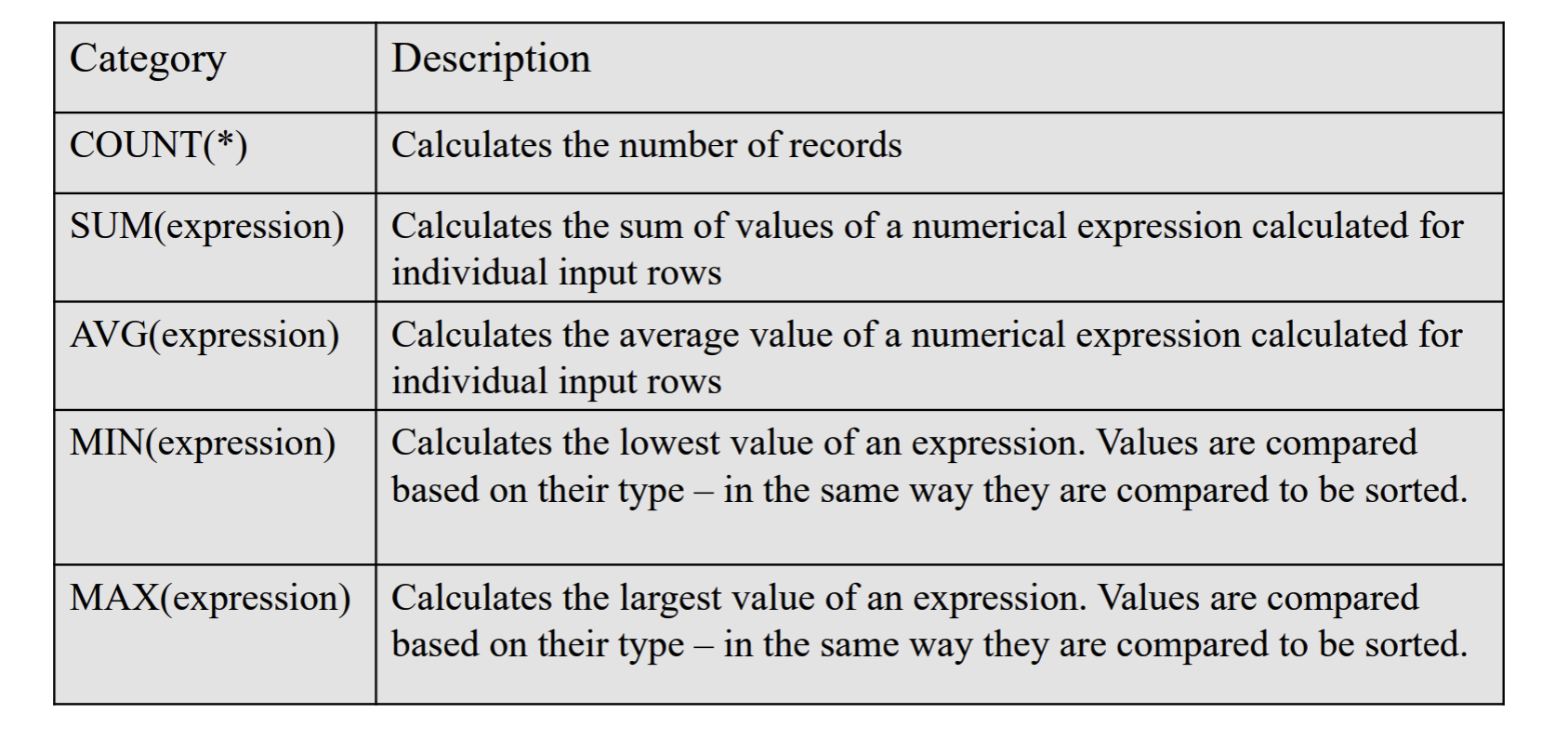
Wykorzystywane do przeszukiwania danych, definiowania struktur danych oraz do uaktualnienia danych.
Istnieje wiele standardów języka, w każdym systemie DBMS implementowane inaczej, przez co pisanie kodu działającego w wielu systemach jest trudne.
SELECT -> służy do wyjmowania danych z tabeli (lub zbioru tabel połączonych relacjami).
select * from rooms where floor in (select floor from rooms b where b.type='lecture')
Lista słów kluczowych
in -> gdy sprawdzasz czy wartość leży w danym zbiorze, może być wykorzystywane na podzapytaniach, ale wtedy zmniejsza się szybkość wykonania like -> pattern match w stringu, słabe wydajnościowo, tutaj lista wzorców tutaj:
1. % - jakakolwiek ilość znaków
2. _ - jakikolwiek znak
3. [b-g] cokolwiek między tymi znakami
4. [ghj] cokolwiek ze zbioru tych znaków
select * from rooms where building like 'Main%'
order by -> na końcu query żeby posortować po wartościach albo alfabetycznie, można order by desc. Można po kilku kolumnach, wtedy rekordy o tej samej wartości w 1 kolumnie będą porównywane przez wartości w drugiej kolumnie itd. select distinct -> tylko unikalne rekordy
Złączanie tabel
Pozwala na wykonywanie operacji na połączonych tabelach
Iloczyn Kartezjański
select * from rooms, buildings where .....
tworzy kombinację każdego rekordu z 1 tablicy z każdym rekordem z drugiej tablicy, konkatenując wartości z kolumn.
Join:
Łączy tylko te kolumny spełniające warunek join ... on warunek
Rodzaje joina:
inner join - tylko te spełniające warunek
left join - spełniające warunek wraz ze wszystkimi rekordami z tabeli parent
right join - spełniające warunek wraz ze wszystkimi rekordami z tabeli złączanej
full join - wszystko złączone z wszystkim
Przykład ze slajdów:
Co tutaj nie tak? -> inner join nie zwróci listy klientów bez zamówień, trzeba zrobić left joina na pierwszym bądź right joina na drugim rozwiązaniu.
Filtrowanie danych z tabeli na podstawie warunku w innej tabeli
exists -> znajdowanie wszystkich rekordów z tabeli rodzica, które mają (lub nie) odpowiednik w innej tabeli
select * from rooms r where exists (select * from assets a where a.room_id = r.room_id)
Algorytm dla powyższego kodu:
Bierzesz rekord wraz z jego id, dla niego wykonujesz podzapytanie “czy istnieje taki asset z tym room id?”
Lista zwrotna pusta? Nie jest na liście wynikowej. Zawiera coś? Rekord zawarty w wyniku.
Złączenie wyników wielu wyszukań
select ... from ...union [all]select ... from ...
złącza wyniki dwóch kwerend w jedność.
All usuwa zduplikowane wartości.
Wymagania do użycia union:
tyle samo kolumn zwracanych we wszystkich podzapytaniach
takie same typy kolumn w podzapytaniach
jeśli wartość kolumny jest podzapytaniem, to trzeba sprecyzować zwracany typ.
Group by
grupuje rekordy o tej samej wartości danej kolumny, pozwala na wykorzystanie funkcji agregujących.
przykład:
select customer_id, count(*), sum(order_value) from Orders group by CustomerID
Tylko kolumny użyte w group by mogą być zwracane w select.
Tworząc wyrażenie group by z wieloma kolumnami, dla każdej kombinacji wartości funkcje agregujące działają osobno.
Having
Nałożenie warunku logicznego na funkcje agregujące z group by:
select CustomerID, delivery_city, count(*), sum(order_value) from Ordersgroup by CustomerID, delivery_cityhaving sum(order_value) > 150
Porównywanie z NULL
where ... column_name is not null
Uwaga na użycie funkcji agregujących z wartościami null, nieoczywiste wyniki.
Widoki
Zapisana kwerenda select.
create view widok as select * from Orders
Wydajność selecta na widoku może być gorsza od selecta na zwykłej tabeli.
Widok to zapisana kwerenda, nie tabela. W trakcie odwołania do widoku DBMS wykonuje podzapytanie. Pozwala ograniczyć użytkownikowi dostęp do specyficznych danych.