Istnieje problem przeszukiwania długich danych tekstowych bądź binarnych. Istnieją procedury do tego, natomiast kolumny tego rodzaju służą raczej do zapisu a nie odczytu danych.
Fajnie by było querować te dane, np. jako kontekst dla LLMów. Natomiast żadna baza (relacyjna, nosQl, nawet pierdolony Hadoop) nie potrafi szybko querować tego typu danych. Rozwiązaniem jest baza wektorowa.
Czym jest baza wektorowa
Przechowuje wysoko-wymiarowe (długie) wektory liczb. Służą do wydajnego przeszukiwania podobnych wektorów. Problem polega w znalezieniu podobieństwa między wektorami (application dependant) oraz w indexowaniu wektorów (nie ma po czym).
Można wykorzystać dostępne bazy wektorowe:
- PineCone
- Milvus
- Qdrant
Bądź zastosować np. PostgreSQL z nakładkami pomagającymi z przetwarzaniem wektorów.
Problematycznym procesem jest również wyświetlenie reprezentacji owych wektorów (np. obrazy), znajdywanie podobnych wektorów oraz wsparcie RAG -> Retrieval - Augmented Generation - system oparty na odpowiedzi na pytania na podstawie zawartości wektorowej bazy danych.
Przykład wykorzystania

typ to embedding vector(n), można selectować po odległości w danej metryce, np. Euklidesowej

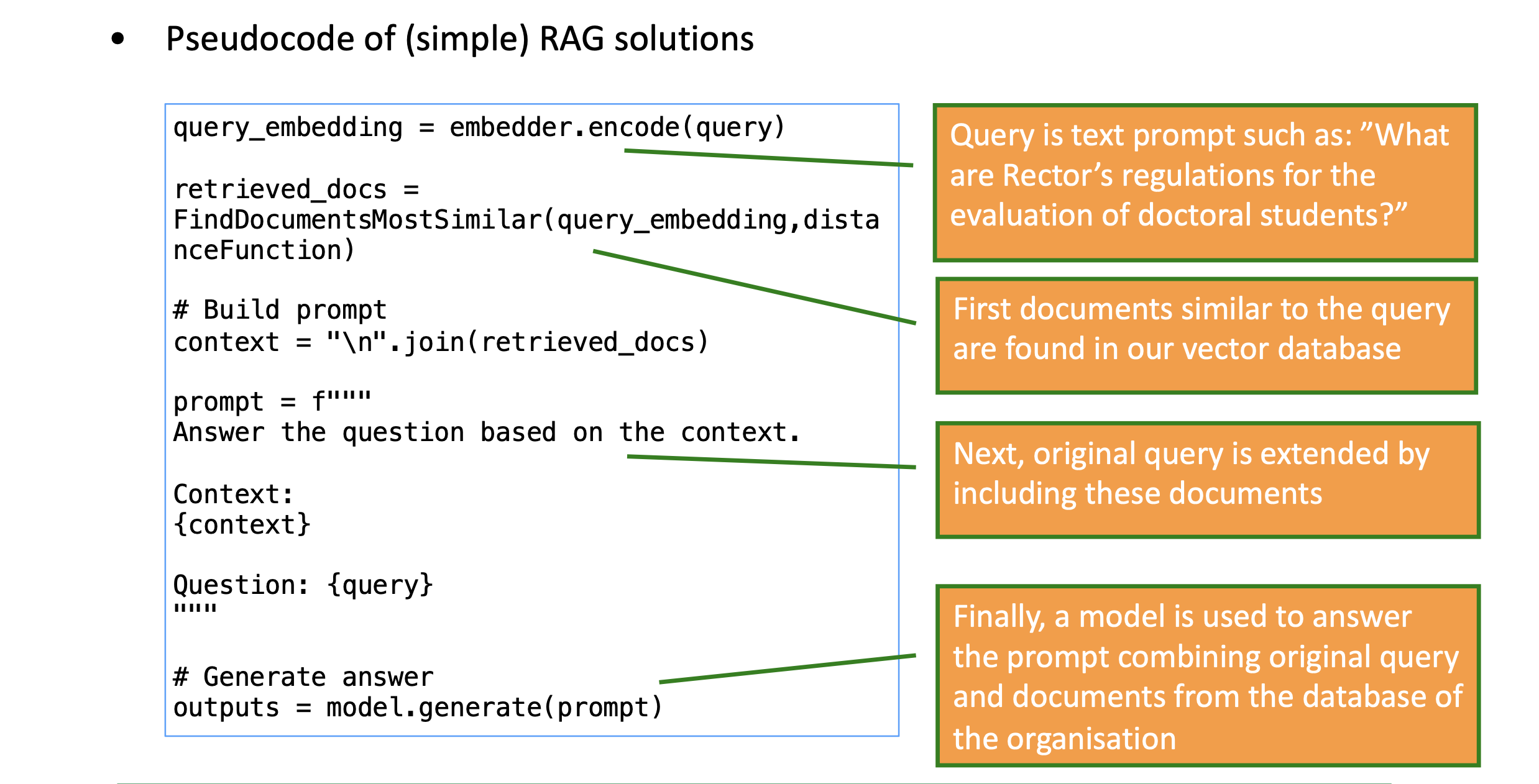
To jest w chuj fajne, tłumaczone jest jak działa RAG. Wpierw bierzesz bibliotekę, która pozwala na zamianę np. tekstu na wektor. Następnie przechowujesz te wektory w bazie danych. Potem gdy chcesz wykonać jakieś zapytanie z nowym tekstem, transformujesz go do formy wektorowej, a potem na podstawie długości np. cosinus wybierasz najbliższe wektory.
Szukanie najbliższego wektora
Skomplikowany proces, znane podejścia to:
- szukanie dokładne (k - nearest neighbor), drogie
- szukanie przybliżone - przybliżanie najbliższego wektora
Proponowane były indeksy polegające na grafach lub listach służących do podzielenia wektorów na listy, najbliższe wektory na tej samej liście.
Pseudokod RAG