Często firmy posiadają wiele instancji DBMS, żeby zachować większe bezpieczeństwo funkcjonalności krytycznych, zwiększyć dostępność popularnych serwisów, bądź utrzymać legacy funkcjonalności.
Podejście file-based
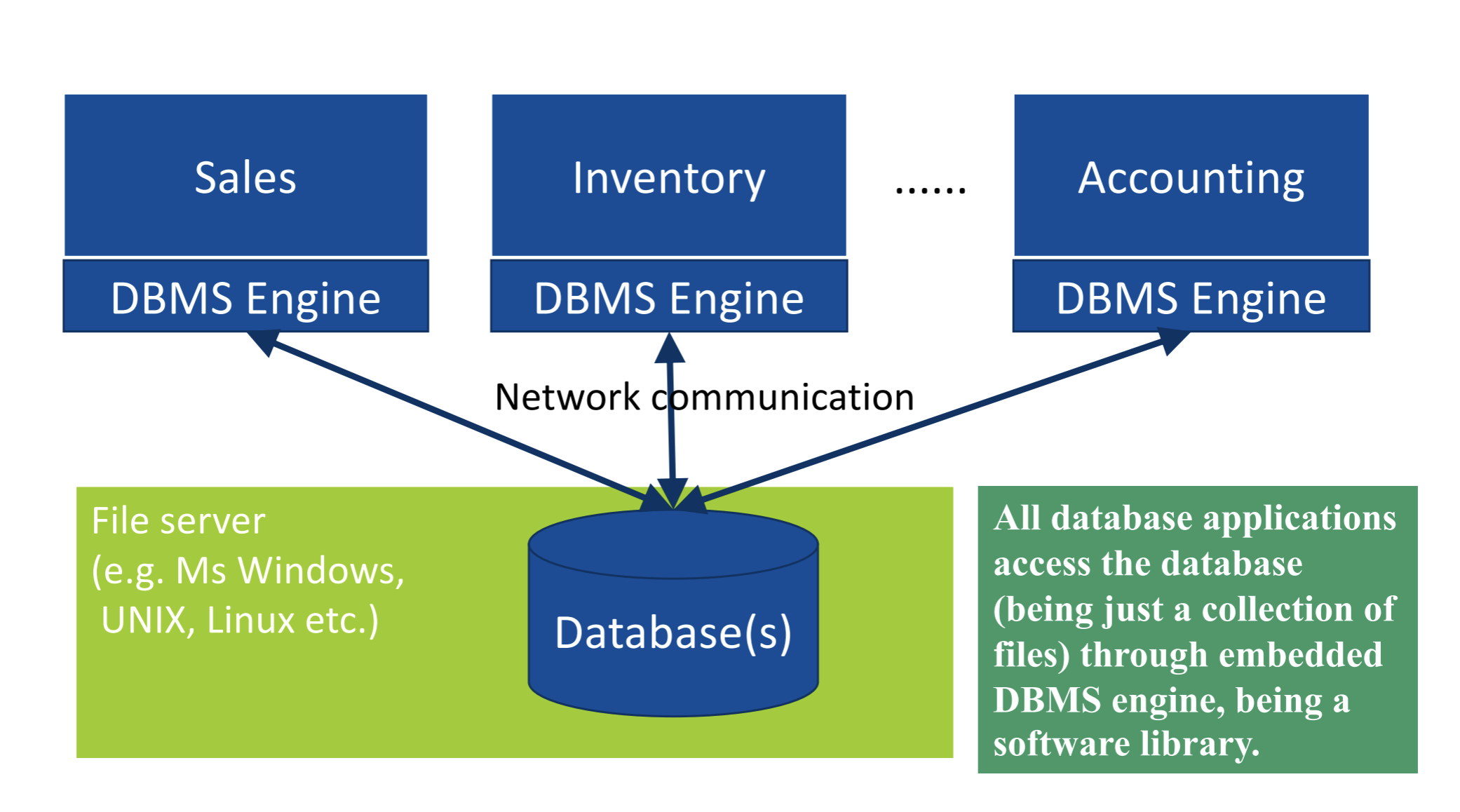
Każda aplikacja zawiera własny embedded silnik DBMS, komunikujący się z bazą danych umieszczoną na jakimś serwerze. Dane są przesyłane przez sieć, a następnie silnik DBMS przetwarza je lokalnie u klienta. Powoduje to bardzo dużą blokadę w trakcie przesyłu danych do wielu klientów. Poza tym, pliki mogą być w całości kopiowane przez użytkowników, bądź utracone w trakcie przesyłu przez sieć. Podejście to nie jest skalowalne na duże systemy.
SQLite
Biblioteka oferująca lekką bazę danych bez serwera, lokalnie na urządzeniu. Napisana w C, sama baza ma mniej niż 1MB. Wspiera procesowanie transakcyjne.
Rozproszone bazy danych
Wiele baz danych rozproszonych po jakimś obszarze, zapewnia lepszą niezawodność, zmniejsza czas oczekiwania na odpowiedź bazy. Wykorzystywane również gdy wiele systemów potrzebuje różnych DBMS albo gdy nie można zapewnić połączenia do jednej centralnej bazy danych.
Architektura DBMS
Istnieje wiele serwerów DBMS ze swoimi lokalnymi bazami danych. Klienci łączą się do najbliższego serwera. Serwery synchronizują miedzy sobą dane za pomocą VPN.
Transakcje rozproszone
Wymagają wiele baz danych bądź wiele DBMS. Nawet jeśli transakcja wymaga modyfikacji dwóch baz danych, które są na tej samej maszynie, to wymagana jest transakcja rozproszona, jako że muszą być spełnione zasady ACID, jest to trudniejsze niż zwykła transakcja.
Do poprawnego przeprowadzenia transakcji rozproszonych wymagany jest proces zarządzający wieloma DBMS, w MSSQL jest to Microsoft Distributed Transaction Coordinator.
Transakcje składają się z dwóch etapów
- prepare phase - koordynator pyta serwery z DBMS czy zmiana jest gotowa do zatwierdzenia. Każdy serwer odpowiada osobno zależnie od tego, czy zmiany u niego się powiodły czy nie.
- commit phase - na podstawie odpowiedzi serwerów koordynator zarządza commit albo rollback u uczestników.
Replikacje
Sposób synchronizacji danych między serwerami. W przypadku transakcji rozproszonych jeśli jeden z uczestniczących DBMS nie odpowiada, transakcja nie może przejść. Natomiast w przypadku replikacji przenoszone są zmiany z jednej monitorowanej tabeli do innych. Jeden serwer może być nieaktywny, tylko że wtedy stan między tabelami na różnych serwerach jest inny.
Rodzaje replikacji
- transakcyjna - zmiany to wyrażenia SQL przesyłane między serwerami
- snapshot - kopia danych z tabeli jest wysyłana
- merge - zawartość DBMS jest regularnie zcalana
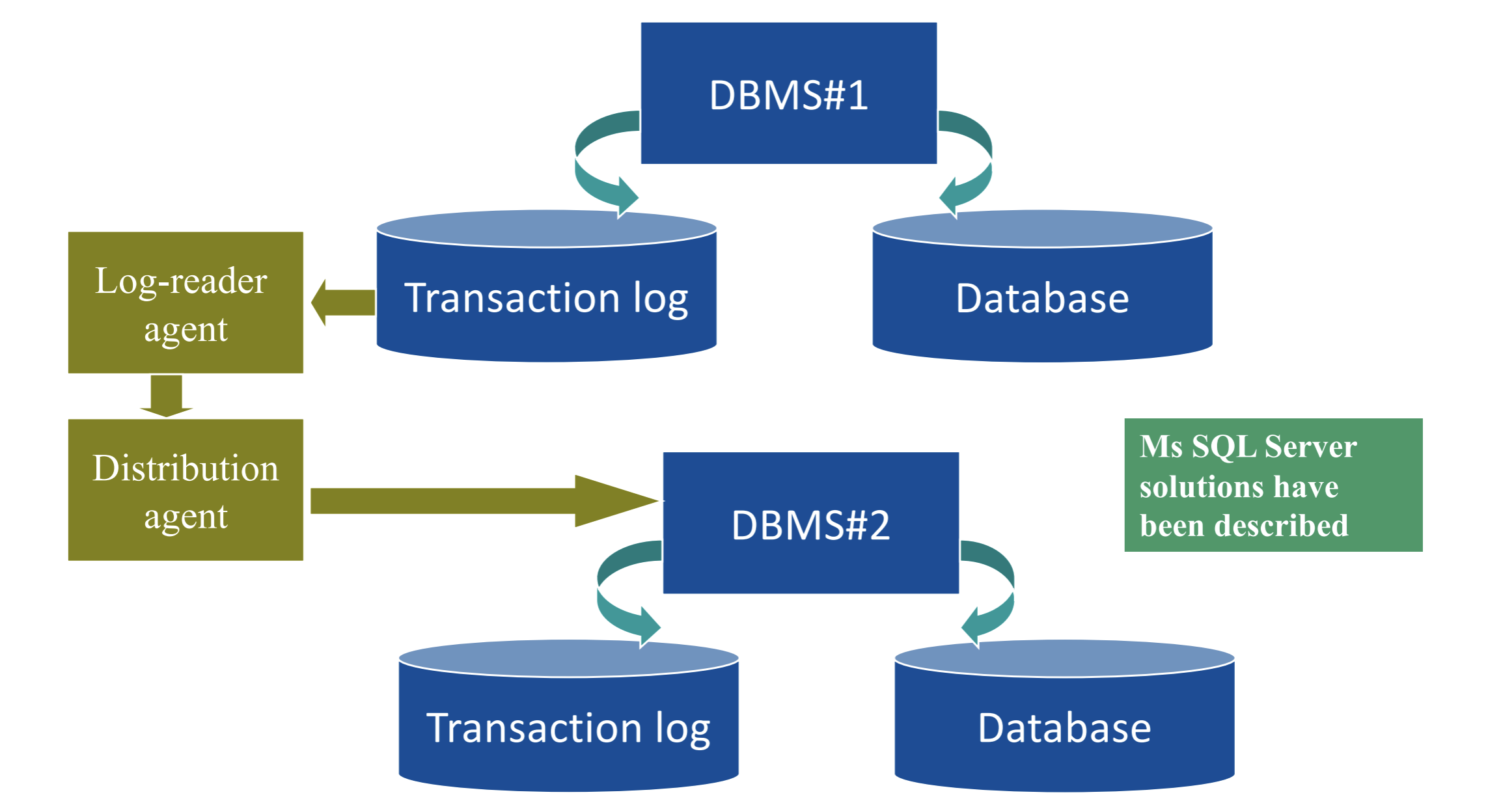
Przykład replikacji transakcyjnej. Czytany jest log, następnie zmiany są umieszczane w bazie dystrybucyjnej, a następnie agent dystrybucyjny rozsyła polecenia SQL do innych baz danych.
HA
High availability - system dostępny 24x7. Potrzebne jest wiele redundantnych urządzeń, takich jak źródła zasilania, ekstra dyski pamięci, wiele interfejsów sieciowych wraz z wieloma połączeniami sieciowymi oraz klastry serwerów. Jest duża różnica między 99% a 99.9% dostępności.
Klaster
Dwa lub więcej serwery podłączone do tego samego zbioru dysków.
Podejścia:
- aktywny/pasywny - pasywny to zapasowy, gdyby pierwszy siadł
- aktywny/aktywny - round robin pracy między dwoma serwerami
Gdy serwer się wywali, pierwsze podejście skutkuje przypadkiem cold failover a drugie hot failover:
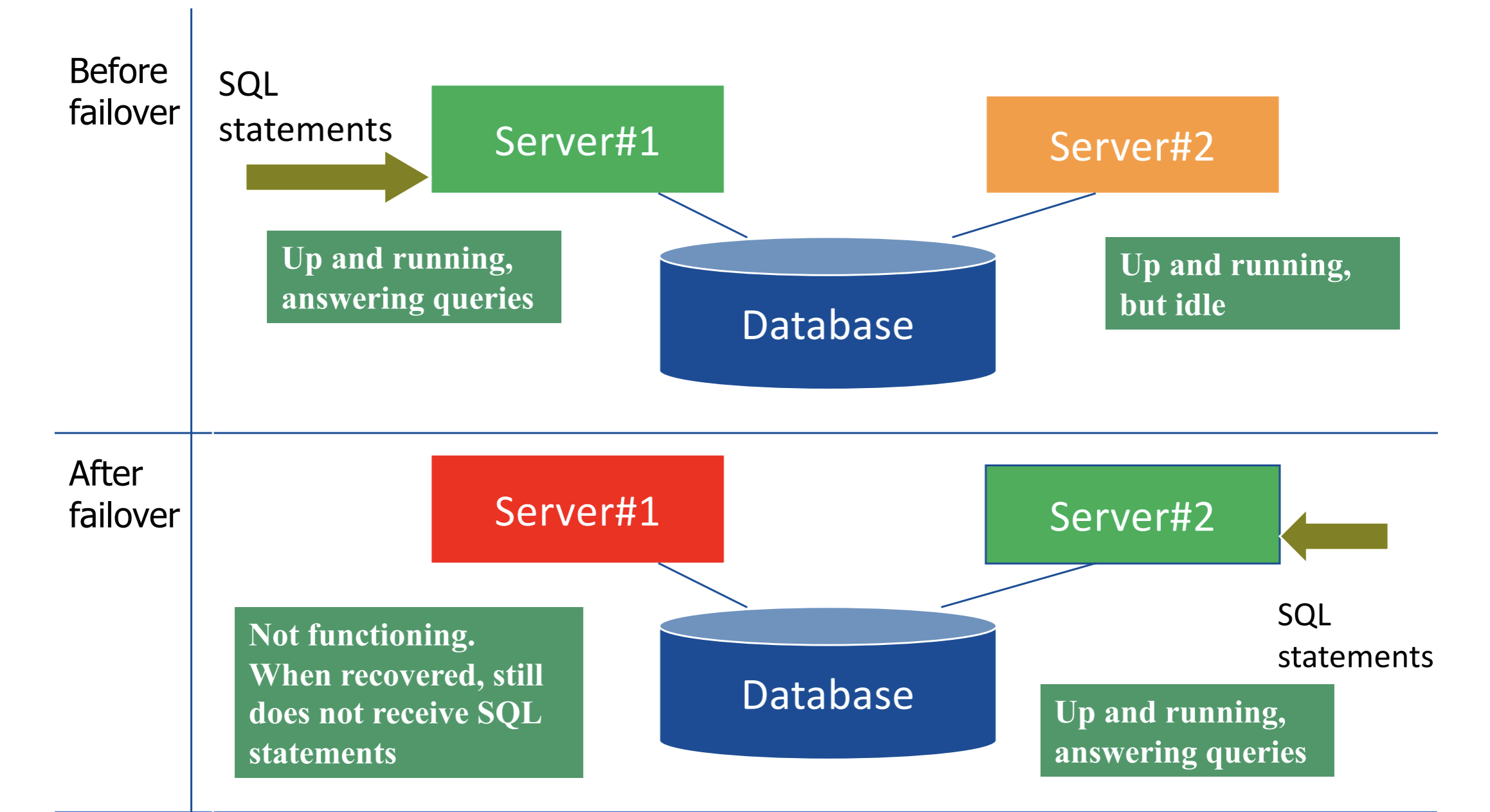
Serwer pasywny był “zimny”, dopiero zaczął procesować wyrażenia.
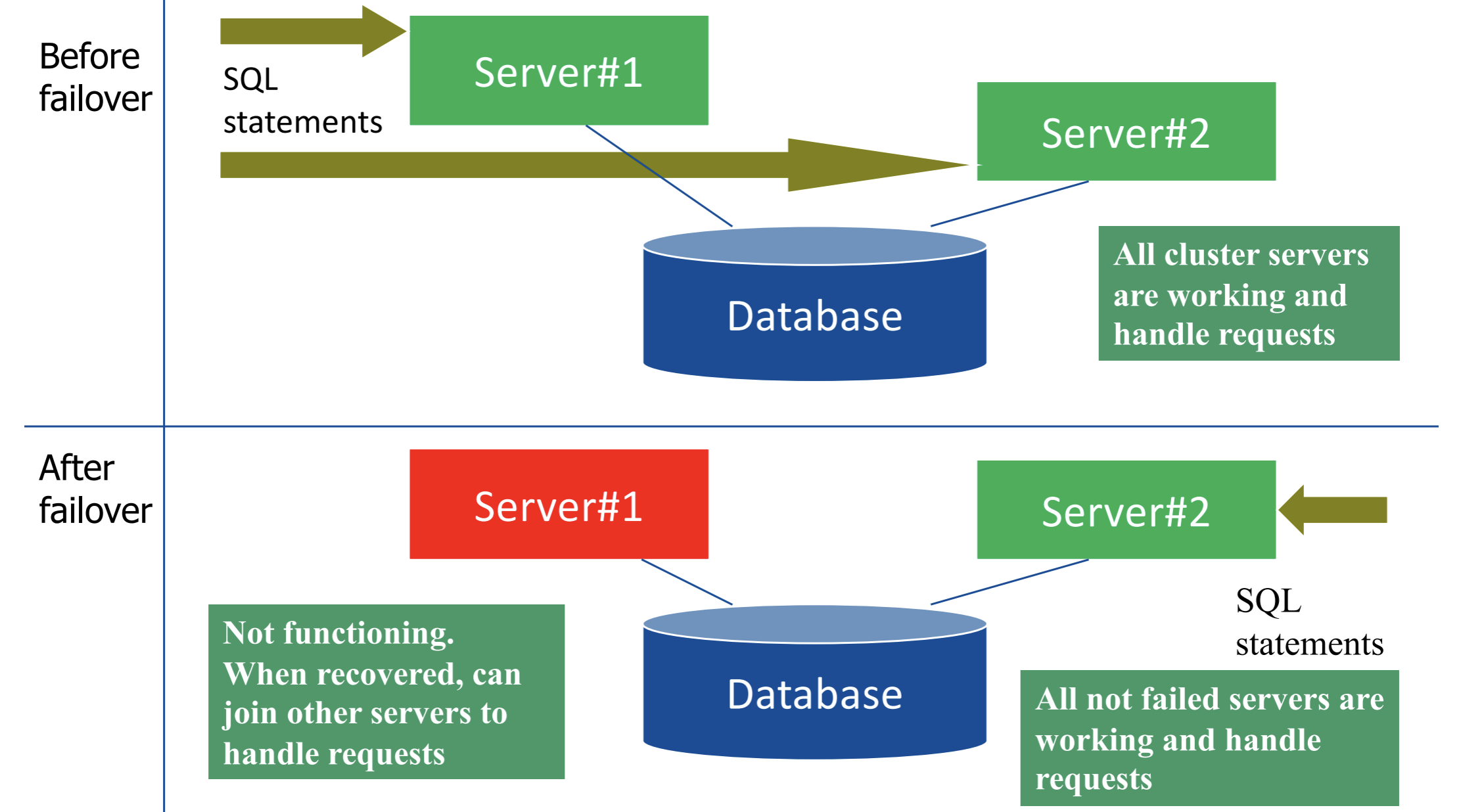
Serwer drugi cały czas obsługiwał polecenia, dlatego był rozgrzany.